Between Mars and Jupiter lies the asteroid belt (aka. the “main asteroid belt”, as there are other areas with asteroids in our Solar System). Within this belt there are millions to billions of asteroids made up of rock and metals. Some are tiny particles but the largest is Ceres which is 580 miles in diameter. Large or small they’re hurdling through space at speeds up to 40,000 mph, so if one flew into a space craft it could be disastrous. Fortunately this isn’t really a problem.
Far Out
Unlike asteroid belts in sci-fi movies, our main asteroid belt is not an obstacle course. Most of the asteroid belt is empty space. The four largest asteroids alone make up more than half the total mass of the entire belt and if you combined all of the asteroids together it would still be smaller than our moon. The average distance between asteroids is around 600,000 miles. According to Alan Stern of the Southwest Research Institute, “… if you want to come close enough to an asteroid to make detailed studies of it, you have to aim for one.” The odds of a spacecraft hitting one is less than 1 in a billion. It’s easier to fly through the asteroid belt than it is to actually hit an asteroid.
Depending on how you count there is 1 or 3 Stanley Cups.
The Stanley Cup, the trophy awarded to the annual champions of the NHL playoffs, was first awarded in 1893. It was commissioned by the Governor General of Canada Lord Frederick Stanley (hence the name). He wanted there to be an annual award/trophy for the best amateur Canadian hockey team. The trophy chosen was a silver rose bowl attached to a single-tiered circular base. Over the years the trophy grew to a multi-tiered base inscribed with the latest winners of the Cup, now awarded to the best professional team in North America. Unlike most major sports which have used different trophies over the years, the NHL uses the same Stanley Cup every year … except when they haven’t.
Presentation Cup
By the 1960s the Stanley Cup (also known as the “The Dominion Hockey Challenge Cup”, or the “Challenge Cup”) had become increasingly battered and damaged after years of being manhandled by players and staff. A clone of the Cup, complete with identical bumps & bruises, was created in secret and replaced the original Stanley Cup in 1970. This new sturdier cup is, for all intents and purposes, the Stanley Cup. It was used for at least three seasons without the players or the public being aware that the original Stanley Cup had been retired. This new Cup is called the Stanley Cup but is also known as the “Presentation Cup” as it’s the Cup presented to the championship winning team.
Upon being retired the original/real Stanley Cup was moved to the Hockey Hall of Fame in Toronto where visitors can see it on display. When the Presentation Cup isn’t on the road it too can be seen in the Hockey Hall of Fame. The public interest to see both on display however created a dilemma: what do you show when the Presentation Cup is on the road? Enter the third Stanley Cup.
The original Stanley Cup (left) and the Presentation Cup (right) on display at the Hockey Hall of Fame.
the Replica Cup
Fans who travel to the Hockey Hall of Fame want to see the original Stanley Cup as well as the Presentation Cup (the new Stanley Cup). To ensure that the two are always present, even when the Presentation Cup is on the road, a third Stanley Cup (the “Replica Cup”) was created. Starting in 1993 the Replica Cup has been displayed in the Hall of Fame whenever the Presentation Cup can’t be. The Replica Cup is identical to the Presentation Cup but with a few engraving mistakes corrected.
So depending on how you count there is one Stanley Cup, or there are three.
Added info: The Stanley Cup(s) are not owned by the NHL. Despite being the crowing achievement of an NHL season, the Cup is actually governed by a trust established by Lord Stanley. At any given time there are two trustees who have “absolute power” over the Stanley Cup.
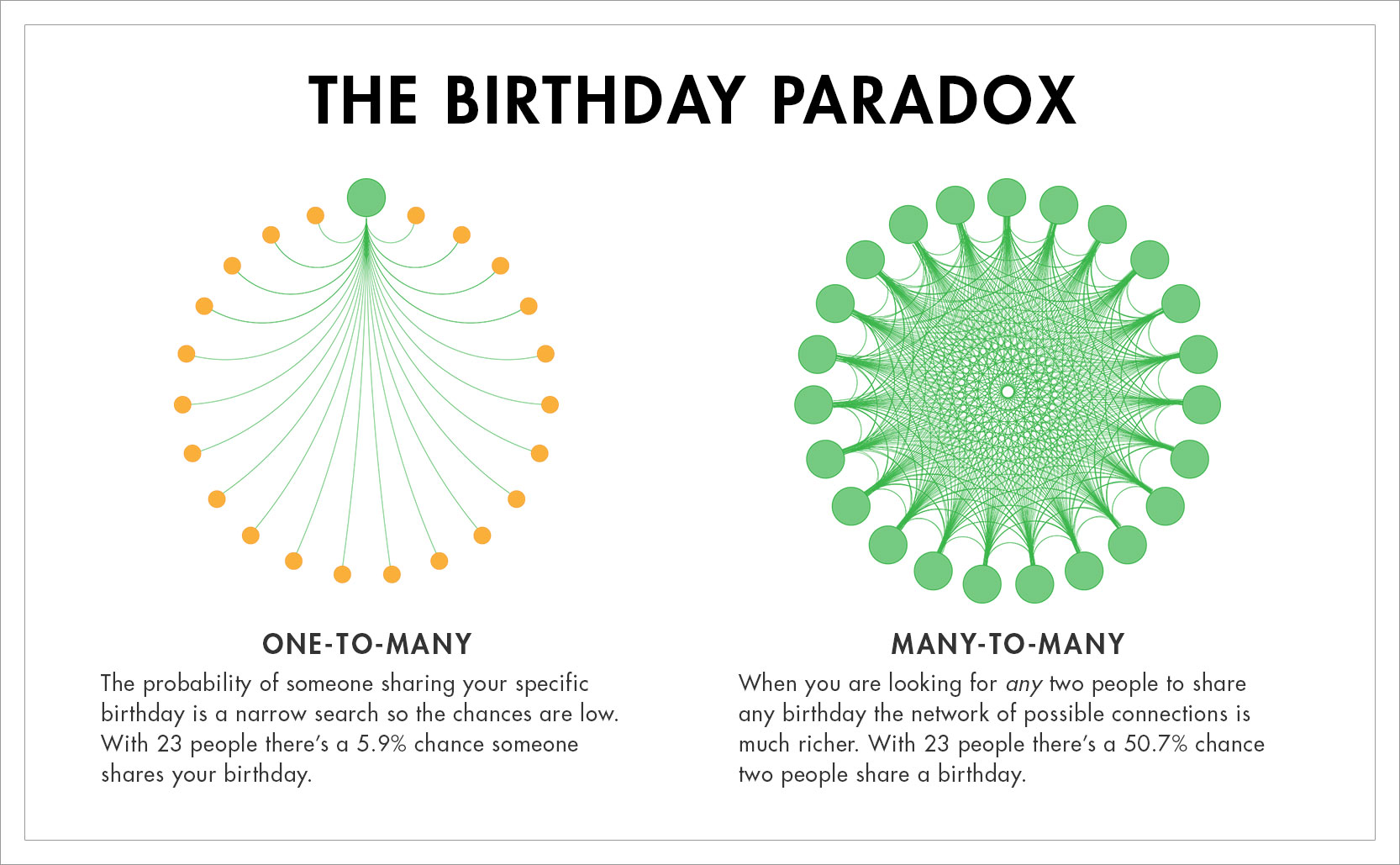
It only takes a group of 23 people for there to be a greater than 50% chance that two people share a birthday.
In any group of people there is a chance that at least two people share a birthday – but what are the chances? Surely it doesn’t take 366 people before two of them have the same birthday, but how many do you need? The Birthday Paradox (aka the Birthday Problem) is so named because it demonstrates our generally poor ability to intuitively reason more complex mathematics. Humans are bad at grasping big numbers, we’re bad at compounding, and as demonstrated in the birthday paradox we’re bad a probability.
Birthday Probability
Because of our poor ability to understand probability people may be surprised to learn that, despite 365 possible birthdays (excluding leap day), it only takes 23 people for there to be a 50.7% chance that two people have the same birthday (factoring in leap days it becomes a 50.6% chance). With 50 people it jumps up to 97%, and by 60 people a shared birthday is all but guaranteed at a 99.4% likelihood.
In a group of people the probability of someone having your birthday is lower than the probability that any two people share a birthday because of the difference between searching one-to-many versus many-to-many.
To explain why it takes so few people it’s important to consider how you approach the problem. If you are thinking of the odds that a single person has your birthday, it’s 1/365 or 0.27% chance (so not very likely). In a group of 23 people the odds that any of them have your birthday is 0.27% x 22 other people, so around 5.9% – still pretty unlikely. However, when you broaden the perspective away from yourself where 23 people are bringing 23 possible birthdays, creating 253 different birthday pairings, where any of them might overlap, now you’re pulling from a much larger probability pool. This many-to-many network of possibilities is how there can be a 50.7% chance that two people share a birthday.
Contrary to folklore salamanders are not born in fire, they aren’t fireproof, nor do they have any affinity for fire.
For thousands of years salamanders have been associated with fire. Aristotle believed that salamanders were so cold they could extinguish fire (a claim later repeated – with skepticism at least – by Pliny the Elder). This claim was later specifically applied to extinguishing the fires of blacksmith forges. The Talmud claimed that smearing the blood of a salamander on yourself could make you immune to the dangers of fire. Leonardo Da Vinci said that salamanders got their sustenance from fire which was also how they repaired their skin. Related to their skin, the Persians claimed that asbestos was the fur of salamanders (Persians would also clean cloth made of asbestos by throwing it into the fire, bringing it back out white again). Alchemists and occultists also associated the element of fire with salamanders. But why?
A collection of salamanders & fire seen over the centuries.
Throw another log on the fire
Being amphibians, most salamanders prefer cool damp places and have no interest in fire. The connection between fire and salamanders is most likely because salamanders hide & hibernate in logs (among other places). People would accidentally use these logs as firewood and, as the salamanders found their habitat suddenly on fire, would scurry from the flames. Not knowing the creatures were hiding in the logs in the first place people interpreted this sudden appearance of salamanders as though they were born in the fire, that they were fireproof, or that they had some special connection to fire, etc. In actuality the salamanders were just running for their lives and most definitely had no special protection from fire.
Symbols
Because of this association with fire, salamanders were sometimes an emblem for blacksmiths. European heraldry also featured a variety of salamanders in fire – sometimes looking like actual salamanders, sometimes looking more like dog lizard hybrids. Heraldic salamanders were used to represent a wide range of attributes from sacrifice, to courage, to resilience, to faith.
Fast-forward to modern day and the association with fire lives on in heating companies and heating unit names. It also lives on in literature such as Ray Bradbury’s Fahrenheit 451 where the firemen have the symbol of a salamander on their uniforms.
A plot device that isn’t as dangerous as movies & TV led us to believe.
Quicksand was once a very common plot device in TV shows & movies. From Lawrence of Arabia to The Incredible Hulk, Gilligan’s Island, Batman, and even in space in Lost in Space, quicksand was all over pop culture in the 1960s. Nearly 3% (or 1 in every 35) movies made in the 1960s featured quicksand. Characters step on what looks to be solid ground but, surprise, it’s quicksand. They begin sinking like they’re going down some sort of Earth elevator with the looming possibility of being totally submerged unless a handy vine or person can save them … this is not how quicksand really works. Real quicksand is not as sudden, dramatic, or dangerous as fictional quicksand.
Quicksand has been a serious, and sometimes humorous, plot device for a long time but was especially popular in the 1960s.
Non-Newtonian Fluid
Quicksand is a mixture of water and sand/silt where the sand particles are suspended in water and spaced further apart than typical sand. It’s a non-Newtonian fluid so if you apply pressure you momentarily change the viscosity. Higher viscosity substances move more like mud, lower viscosity substances move more like water. In quicksand’s case stepping on it with your foot applies pressure and changes the viscosity to become momentarily less viscous. The sand particles get pushed out of the way making it more watery, which allows your foot to sink. This is quickly followed by the sand settling into place around your foot which is how you get stuck. The more you move, the more you agitate the mixture, the deeper you go.
The Good News
You can not totally sink into quicksand like some sort of bottomless pit. One reason is that quicksand is rarely more than a few feet deep. Further, the human body is less dense than the density of quicksand which means that, regardless of the quicksand depth, it’s not possible to sink further than your waste. That said there are dangers.
Since quicksand can form beside larger bodies of water there is the possibility of drowning due to flash flooding, tidal changes, etc. Other dangers include hypothermia, sunburn, predators, and/or the pain of having part of your body under pressure for a prolonged period of time. Most of the time though quicksand is fairly harmless as long as you stay calm to get out of it.
To get out of quicksand the first thing you should do is to not go any further in – stop moving around. If you can’t use your other foot to just step back out, and you really feel stuck, it’s time to sit/lay down extending away from the quicksand. Making yourself wider reduces the focalized pressure into the quicksand which helps free your foot. Then slowly work your leg back and forth, lowering the viscosity & making the quicksand more watery, and patiently pull your leg out.
Bonus: The “King of Quicksand” has a whole YouTube channel devoted to intentionally getting stuck, and then escaping from, quicksand. Watching any of his videos shows that you really have to work to get yourself stuck in quicksand, which is reassuring.
You can also watch a playlist full of scenes from TV shows and movies (old and new) of characters getting stuck in quicksand.
Treasure Island is largely responsible for why we think pirates buried treasure, but they didn’t.
Robert Louis Stevenson’s 1883 tale of pirate adventure, Treasure Island, has done more to shape our idea of colonial era pirates than anything else. How we think pirates dressed, how they behaved, to how they spoke (although some of that was English actor Robert Newton’s exaggerated West Country accent in the 1950 film adaptation – which is the basis of most “pirate speak”), Treasure Island basically defined the pirate genre. It also popularized the fictional idea of treasure maps and buried treasure.
You can’t bury perishables
Pirates didn’t bury treasure for a host of reasons. For one, if they were lucky enough to raid a ship loaded with money or jewels they turned around and spent it – it didn’t stick around long enough to be buried. A bigger reason however was that gold, silver, & jewels were a small fraction of what pirates typically got to steal. Most looted booty was normal trade goods (sugar, alcohol, dyes, tobacco, cloth, timber, food, etc). The seas were the highway system for moving all manner of commercial merchandise and most of what pirates stole would rot if left to sit around for extended periods of time (burying these goods being even worse). It was more typical that pirates would sell their loot in port towns and, again, immediately squander the money they earned. Most pirates never accumulated enough wealth to even have the option of burying it somewhere.
The buried pirate treasure of Captain Kidd is the one exception to the rule that pirates never buried treasure.
It’s a myth, except …
Ultimately it’s a myth that pirates buried treasure … but with one famous exception. In June of 1699 Captain William Kidd, while sailing to New York where he knew he was a wanted man, took the preventative measure of burying some pirated treasure on Gardiners Island off the East end of Long Island. He hoped to use this treasure as leverage in his future trial, which failed as he was eventually convicted of piracy and executed.
Added info: You can find a copy of Treasure Island in lots of places but it’s also available for free as an audio book on archive.org.
North America lobsters were originally a poor person’s food.
While an expensive luxury today, the American lobster (aka Homarus americanus, the Maine lobster, Canadian lobster, northern lobster, etc) was once a food of last resort. Native American tribes of the northeastern coastal regions would use lobsters as fertilizer, fish bait, and when necessary food. European colonists also viewed lobsters as inferior last-resort bottom feeders. These “cockroaches of the sea” became relegated to food for the poor, for servants, prisoners, slaves, and sometimes even feed for livestock.
The turnaround for lobsters began in the 19th century with two new industries: canning and railroads. As canning became a viable way to preserve & ship food, lobster meat became a cheap export from the New England area. Lobster meat was sent via rail to locations all around North America. This was followed by tourists visiting New England along some of the same rail lines. These tourists were able to finally taste fresh lobster meat instead of canned and lobster’s popularity grew. By the 1880s demand for lobster (especially fresh lobster which must be shipped alive) combined with a decrease in supply, lead to higher prices. This helped establish lobster as the expensive delicacy we think of today.
Expensive?
Like any commodity, lobster is subject to price fluctuations. While lobster typically maintains its cultural status as an expensive delicacy, this doesn’t always reflect the real cost. For example the over abundance of lobsters around 2009 sent the wholesale price of lobster from around $6 a pound to half that – but it would have been hard to notice. Restaurants don’t typically reduce their prices because an ingredient has suddenly become cheaper.
However, when lobster is less expensive it does appear in unexpected places. Around 2012 Gastropubs included lobster in dishes such as macaroni & cheese, fast food chains included lobster on their menus, Walgreens in downtown Boston even sold live lobsters – all things you don’t usually see when a commodity is expensive. Today, even in years when lobster is abundant and the cost is low, it is still thought of as a luxury item.
Sparkling wines range from dry to sweet based on how much sugar is added after the second fermentation.
The most well known kind of sparkling wine is Champagne which not-so-coincidentally comes from the Champagne region of northern France. The word “Champagne” is a protected designation of origin (PDO) term which means only sparkling wine from the Champagne region of France may be legally called “Champagne” (as per a a rule included in the Treaty of Versailles in 1919). As such other countries have their own regional names for sparkling wine. The Spanish call their sparkling wine Cava, the Germans and Austrians have Sekt, the Italians have Spumante but their better known protected designation of origin variety of sparkling wine is Prosecco, etc. The one exception is the United States who never ratified the Treaty of Versailles and have been free to call their sparkling wine Champagne ever since (although in 2006 the issue was revisited and the US agreed to some limits, but established American companies calling their sparkling wine Champagne were allowed to continue doing so).
While there are a variety of methods to making sparkling wine, they all start with making wine. This is followed by adding a little sugar & yeast to each bottle to generate a second fermentation. This second fermentation, which takes place in the capped bottle, is what produces the CO2 bubbles sparkling wine is known for. Depending on the production method, wine makers then add a mixture known as “le dosage” at the end before the final corking. Dosage is a sweet mixture of still wine and sometimes sugar to balance out the flavor of the sparkling wine. How much dosage is added makes all the difference.
Sparkling Sweetness
The sweetness of a sparkling wine is determined by how much sugary dosage is added – the more sugar, the sweeter the sparkling wine (makes sense). To know how sweet a sparkling wine is, wine makers label their bottles with a variety of terms. Unfortunately, different countries use different words to convey the same general idea. The following is an explanation of sparkling wine sweetness terms.
Sparkling wines range from brut to doux. Brut comes from the French for “dry” or “unrefined”. There is some overlap in Brut categories depending on the wine maker but they are all fairly unsweet sparkling wines. Doux comes from the French for “soft” or “sweet”. These bottles are the candy aisle of sparking wines.
Added info: the most famous early sparkling wine was by the 17th century monk Dom Pérignon, however sparkling wine originated in England. In typical wine bottles, sparkling wine has the tricky problem where the second fermentation inside the bottle builds up enough pressure that the bottle can explode. Because 17th century English glassmakers used coal in their glass production they could produce a stronger bottle which allowed them to reliably produce sparkling wine before the French.
Part of the survival strategy of cicadas is to emerge in prime number intervals.
There are thousands of species of cicadas. As nymphs they live most of their lives underground, only to emerge when they are ready to transform into adults, sing, mate, and die. Their time above ground is about a month.
Broadly speaking cicadas can be divided into two groups: • Annual cicadas: those with relatively short life cycles, some of which appear every year • Periodical cicadas: those that live underground for over a decade and only come above ground in synchronized intervals
Periodical cicadas are found only in the eastern areas of North America. Instead of a few here and a few there coming above ground every year, periodical cicadas (divided up into 15 geographic broods) appear all together at designated intervals. Their synchronized appearances, every 13 years or every 17 years, is what makes them remarkable.
Prime Number Survival
Part of the survival strategy of the periodical cicadas is that they appear all together. Millions to billions of cicadas all emerging in the same short window of time ensures that, while many will be killed by predators, the majority will survive to continue the species. Simply put, there are so many cicadas appearing all at once that predators can’t eat them fast enough – a survival concept known as predator satiation.
Predator satiation is a numbers game. It only works in large numbers relative to the number of predators. For a brood of periodical cicadas this means they have to be synchronized and appear all at the same time otherwise their numbers might be too low, too many may be eaten, and they could die off.
What a brood of periodical cicadas doesn’t want is another brood appearing at the same time. For one thing they would be competing for resources. What’s worse is if a 13 year brood and a 17 year brood interbreed then the inner clocks of their offspring may become confused. The result could ruin the synchronized timing of their appearances which they need for predator satiation. Their survival depends on avoiding other broods of cicadas. Enter, prime numbers.
Taking into consideration reasonable lifespans for cicadas, composite number intervals would have broods appearing in the same year more frequently than the prime number intervals of every 13 or 17 years.
Prime numbers are numbers only divisible by themselves and 1. The periodical cicadas of North America appear in prime number intervals of either 13 or 17 years. If you create a list of years, and mark every 13 years as well as every 17 years, they rarely overlap. In fact, 13 year cicadas and 17 year cicadas only overlap every 221 years. If they appeared in composite number intervals, (4, 6, 8, 9, etc) they would overlap constantly and most likely die out. Through evolution, the periodical cicadas that used prime numbers have survived.
The terms we use for different letterforms come from how they were stored.
In the beginning, there were capital letters (majuscule letters). The written languages of the Ancient Greeks and Romans were both in all caps. The Roman square capitals and the Roman calligraphic script eventually generated Uncial script. Uncial was used between the 4th and 8th centuries and continued the style of all caps. Around the late 8th century however, the Benedictine monks of Corbie Abbey in France began using a new style of writing which became the Carolingian script. Carolingian could be written faster than Uncial script because it used a new style of letters: lowercase (minuscule letters). What this meant was that some European countries now had two different styles for each letter of the alphabet. These different letterforms meant the same things, and were pronounced the same ways, but they looked different.
While these letterforms started off isolated to their respective styles of writing, over the centuries they began to commingle. This merger of letterforms was partially inspired by the decorative initial caps in illuminated manuscripts. It wasn’t until the 14th century that grammatical rules began to define when to use a majuscule letterform in otherwise minuscule text (such as capitalizing the start of a sentence, or someone’s name, etc).
Uncial script on the left (a portion taken from The Book of Kells) compared to Carolingian script on the right.
Majuscule minuscule, uppercase lowercase
Johannes Gutenberg introduced the printing press to Europe in 1439. The printing press allowed individual metal letters to be assembled together to print information. All of these metal letters were organized into trays/drawers/cases. The majuscule letters were used less often and so were placed higher up. The minuscule letters were used the most and were placed the closest to the worker setting the type. Because of their position these higher elevated majuscule letters became known as “uppercase” while the easier to reach minuscule letters became “lowercase.”
A 20th century type drawer/case.
An explanation of uppercase and lowercase letters and how these terms originated with the printing press.
Added bonus: Not all languages have uppercase and lowercase letters. Unicase languages include Arabic, Hebrew, and Georgian to name a few. That said, while Arabic doesn’t have the capitalization rules that Latin derived languages now have, Arabic does utilize the IMFI writing system. Based on the position of the letter in a word or sentence (initial, medial, final, or isolated), one of four different shapes are used. So instead of the two letter form variations that the Roman alphabet has Arabic has four but for different reasons.